- 必要なソフトをダウンロードとインストールを行います。
$ sudo apt update
$ sudo apt upgrade
$ sudo apt install curl
$ sudo apt install git
$ sudo apt install sra-toolkit
$ git clone https://github.com/akiomiyao/ped.git
- Ubuntuのバージョンによっては、sra-toolkitのインストールに失敗することがあります。
また最近のバージョンのfastq-dumpは使用前にvdb-configコマンドで実行環境を設定する必要があります。
設定方法は、[fastq-dumpの設定]のページに記載しました。
- NCBIのSRAアーカイブからサンプル名 IDH-06641のfastq形式のファイル(DRR178327)をダウンロードします。
上記サンプル名のリンクをクリックして表示される25系統の配列を解析すれば、非O1、非O139コレラ菌のゲノム比較解析ができます。
$ cd ped
$ git pull
$ perl download.pl accession=DRR178327
git pullで最新のスクリプトに更新されます。git pullは毎回行う必要はありませんが、プログラムが更新されている場合はpullしてください。
pedのディレクトリの中に、DRR178327の名称のディレクトリができて、その中のreadというディレクトリの中にfastqファイルがダウンロードされます。
アメリカからのダウンロードなので時間がかかります。
時々エラーが表示されますが自動的に再接続されるので、気長に待ちます。
- DDBJのDRAからもダウンロードできます。
DDBJからのDRR178327のダウンロード
2行目のFASTQをクリックしてbz2形式で圧縮されたファイルをダウンロードします。ダウンロードしたファイルを DRR178327/read のディレクトリに置きます。解凍する必要はありません。
同様の構造の任意の名前のディレクトリを作れば手持ちのデータの解析ができます。
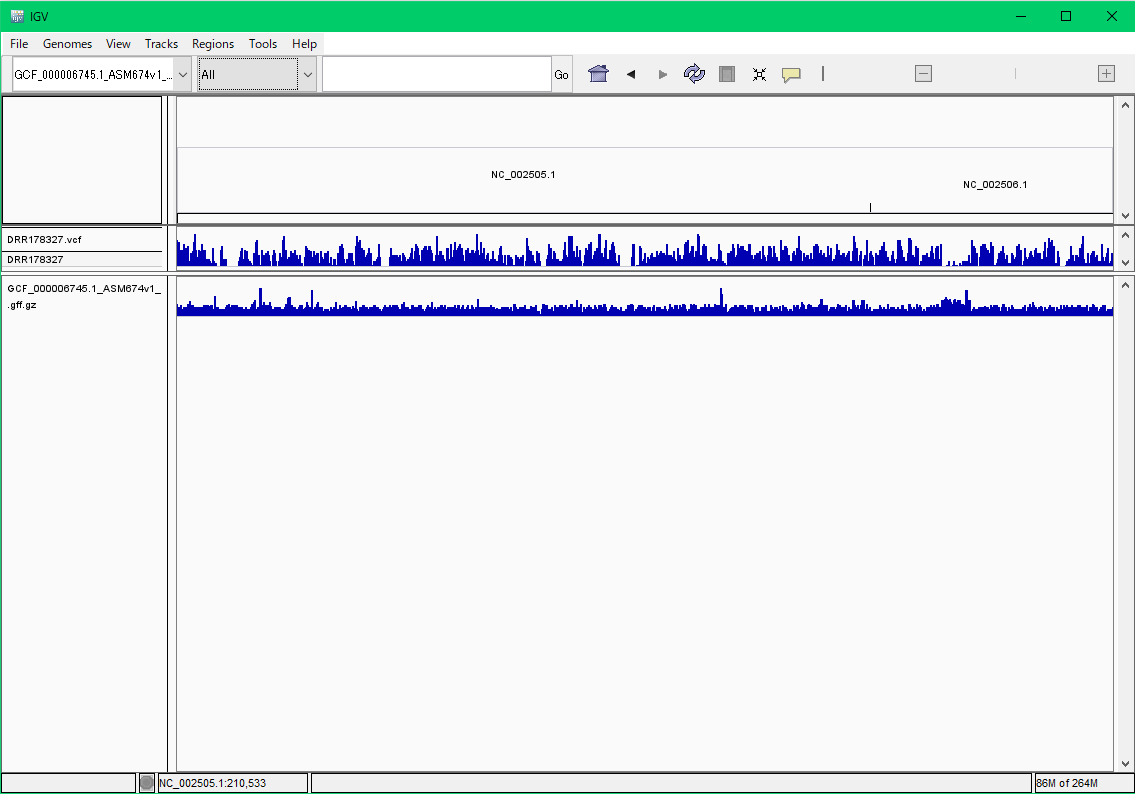
- DRR178327の配列をコレラ菌の参照配列Vcholeraeにマップして多型を検出します。
$ perl ped.pl target=DRR178327,ref=Vcholerae
コレラ菌の参照配列は設定済みなので自動的にダウンロードして解析用データを作成して一連の作業が自動的に進みます。
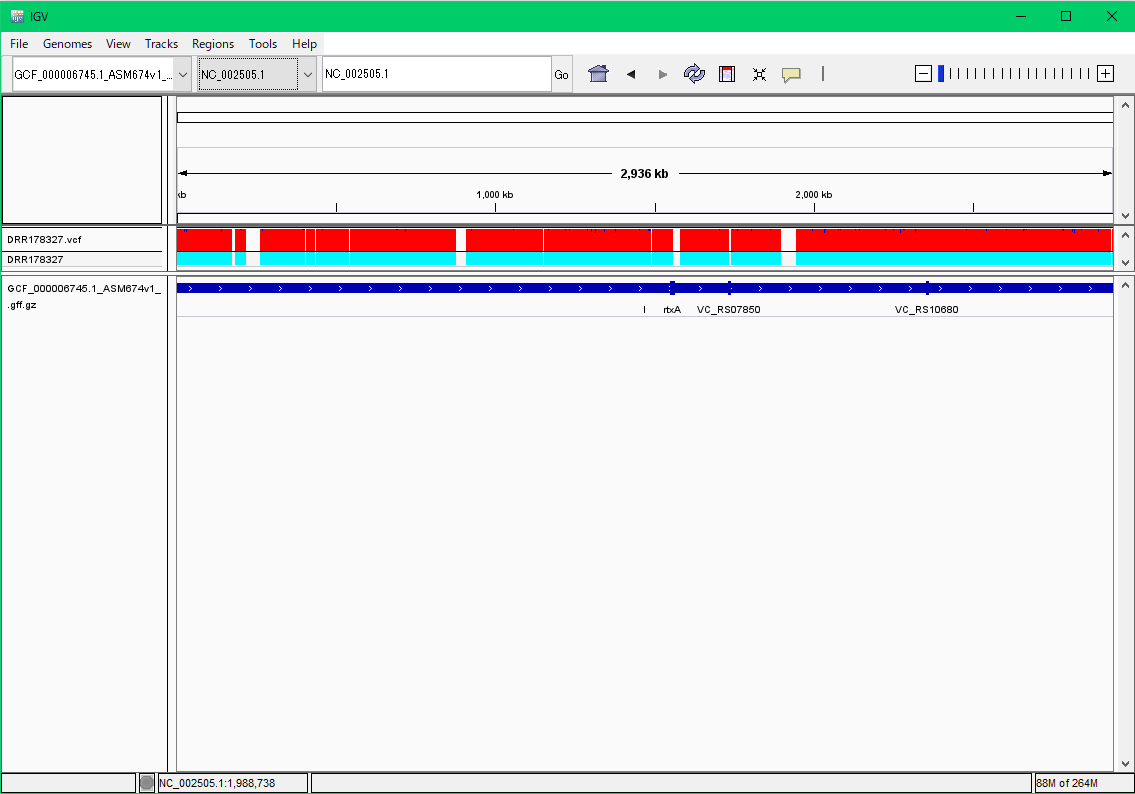
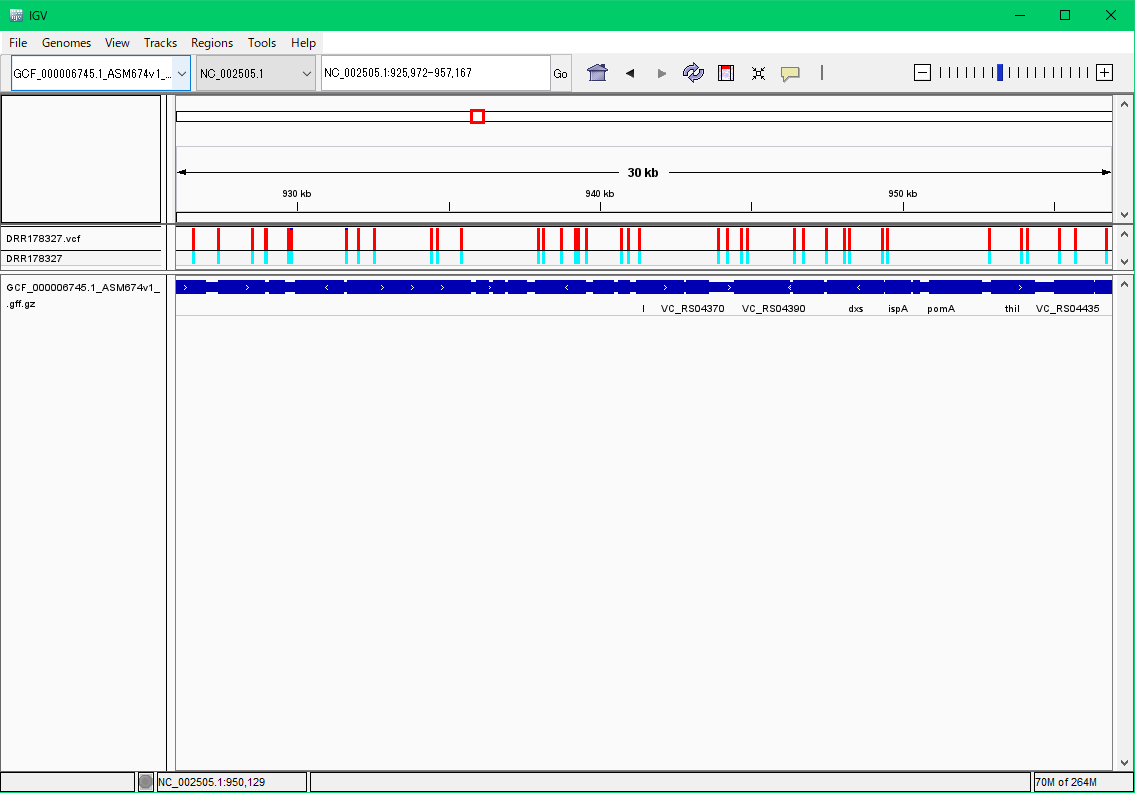
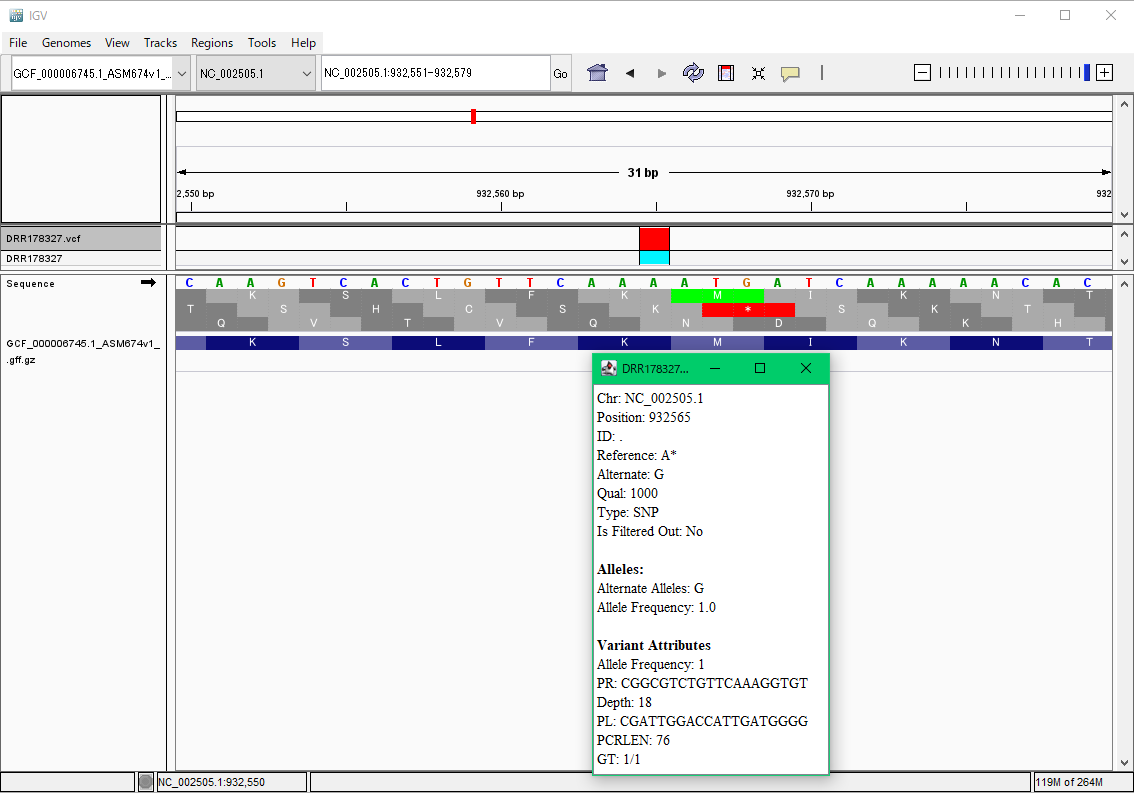
解析が無事終わるとDRR178327のディレクトリの中に、DRR178327.vcfという結果をまとめたファイルができます。
各座位に対してプライマーが作成可能な場合は、プライマーペアの配列データも出力されます。